
超越Gemini3、GPT5.1!阿里千问登顶空间推理全球冠军
- 2025-11-26 17:29:36
空间推理基准测试SpatialBench更新了最新一期榜单,阿里千问的视觉理解模型Qwen3-VL、Qwen2.5-VL位列头两名,超越Gemini 3、GPT-5.1、Claude Sonnet4.5等国际顶尖模型。
SpatialBench榜单显示,Qwen3-VL-235B和Qwen2.5-VL-72B分别斩获13.5和12.9分,领先于Gemini 3.0 Pro Preview(9.6) 、GPT-5.1(7.5)、Claude Sonnet 4.5等海外顶尖模型。
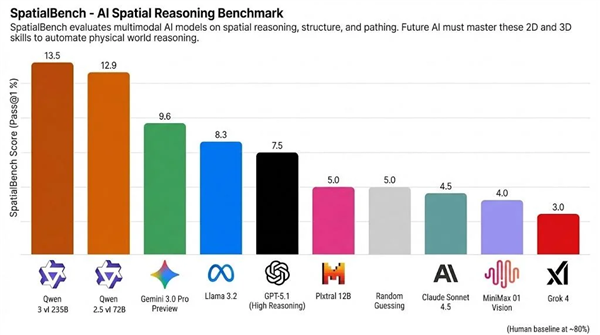
然而,AI大模型的整体表现距离人类仍有差距,人类基准线约为80分左右,可专业处理电路分析、CAD 工程和分子生物学等复杂空间推理任务,目前大模型还无法完全自动化完成此类工作。
据悉,Qwen2.5-VL于2024年开源,Qwen3-VL是阿里在2025年开源的新一代视觉理解模型。
Qwen3-VL在视觉感知和多模态推理方面实现重大突破,在32项 核心能力测评中超过Gemini2.5-Pro和GPT-5,不但可调用抠图、搜索等工具完成“带图推理”,也可以凭借一张设计草图或一段小游戏视频直接“视觉编程”。
同时,Qwen3-VL专门增强了3D检测能力,可以更好地感知空间,基于Qwen3-VL,机器人更好地判断物体方位、视角变化和遮挡关系,实现远处苹果的精准抓取。
目前,Qwen3-VL已开源不同版本,包括2B、4B、8B、32B等密集模型以及30B-A3B、235B-A22B等MoE模型,每个模型都有指令版和推理版两款,是当下最受企业和开发者欢迎的开源视觉理解模型。同时,Qwen3-VL模型也已上线千问APP,用户可免费体验。
据了解,SpatialBench是一项近年来兴起的第三方空间推理基准测试榜单,主要聚焦多模态模型在空间、结构、路径等方面的综合推理能力,被AI社区视为是衡量“具身智能”进展的新兴测试标准之一。
SpatialBench不仅测试模型已知的知识,还测试模型在二维和三维空间中“感知”和操控抽象概念的能力,这对具身智能的落地尤为关键。
相关文章

人才科创中心:链接长三角科创资源 赋能新质生产力")




最新
- 3天前
政策东风已至,院士团队加持,四川具身人形机器人科技有限公司抢占情感交互机器人新赛道
- 3天前
暖城鄂尔多斯(上海)人才科创中心:链接长三角科创资源 赋能新质生产力
- 3天前
圆桌论道、媒体聚焦,具福科技领跑数字中国建设峰会
- 3天前
从蓝图到现实 | 凯傲集团出席中德物流技术交流会,共话仓储未来
- 3天前
华硕商用亮相教育装备展:六大场景展示AI算力赋能教育数字化
- 3天前
山水智城・湾顶明珠|中新广州知识城优质人居文旅用地杭州推介会圆满举办
- 3天前
告别伪智能:追觅硅谷发布会,重新定义庭院的下一个十年
- 3天前
极速跃迁 X 顺丰苏南,共启AI机器人+智慧物流新局
- 3天前
菲博亮相CCMT,焕新智造实力
- 3天前
灵境启元·共生未来:30多年前的预言,在漕河泾开发区照进现实
- 3天前
李长荣Lacyon™鞋大底循环材料首秀2026国际橡塑展,可持续解决方案赋能产业链绿色转型
- 3天前
AI智能战略广交会全球首发!奥克斯空调全球化再次进阶领跑
荐读
-
 AI智能体重构传播链路,媒体管家上海软闻以技术驱动媒体公关业务逆势增长
AI智能体重构传播链路,媒体管家上海软闻以技术驱动媒体公关业务逆势增长
在流量红利见顶与注意力极度碎片化的双重挑战下,2026年春节后的公关传播市场正经历着一场深刻的“洗牌”。当传统的人工邀约模式因效率低下逐渐被品牌方摒弃时,媒体管...
-
 还能这么“玩”?2025首届国际人形机器人街舞邀请赛高光时刻
还能这么“玩”?2025首届国际人形机器人街舞邀请赛高光时刻
机器人跳街舞,这是认真的吗?这不是一场传统的街舞Show,甚至舞台上“人”的元素都被弱化了,但它就是被朋友圈刷爆了,被媒体圈围观了,被大众们圈粉了!没错,街舞还...
-
 网信部门查处一批APP:AI生成合成内容标识违法违规
网信部门查处一批APP:AI生成合成内容标识违法违规
“网信中国”发文称,网信部门依法集中查处一批存在人工智能生成合成内容标识违法违规问题的移动互联网应用程序。网信部门依法依规予以约谈、责令限期改正、下架下线等处置...




